
Digital Object Identifiers (DOIs) are unique names assigned to research outputs and other information resources that are represented in some way on the Internet. DOIs represent an established international information standard, ISO 26324:2012, and many publishers, data centers, and other information providers rely on this standard to assign unique identifiers for works under their care. The DOI assigned to a given research object distinguishes it from other works, including other versions of the same intellectual material. Examples of research-related information resources assigned DOIs include journal articles, curated datasets, theses, conference papers, pre-prints, technical reports, and books.
DOIs are actionable on the Internet: when put in URL form (http://dx.doi.org/{DOI}, these strings automatically redirect to an online landing page that offers information about the research object. Often, but not always, the landing page contains a link to the resource itself. Where the resource is not online, the landing page indicates where to find it. For example, a DOI assigned to a physical resource such as a print book, a museum specimen, or a of scientific sample will specify the repository or collection where the resource resides.
The DOI is NOT by itself a seal of quality. Yet information resources that are assigned DOIs tend to be of enduring value; are likely to be used and cited by others; and are maintained by a publisher or other information provider who is committed to curating and preserving the resource over time. Because an organization is committed to curating the resource over time, the DOI is considered persistent. Some say that the DOI is basically a promise to always supply information about the information resource associated with the identifier.
A DOI is considered a persistent identifier because it reliably resolves to a human- and machine-readable landing page representing the information resource. But the DOI itself is not a guarantee that the dataset or paper is available via Open Access: rather, the DOI resolves to an Open Access landing page that may (or may not) permit linking through to the desired object. Whether or not a user can access the full content depends on various circumstances unrelated to the DOI system: format of the resource, restrictions and conditions governing access; authentication requirements; software compatibility; etc.
Nonetheless, the metadata associated with the DOI is rich enough to provide useful data for researchers. DOI metadata can tell alot about what has been published, who has published it, under what conditions (with what funding, whether the work is available open access, whether the work has been updated since publication, and more.)
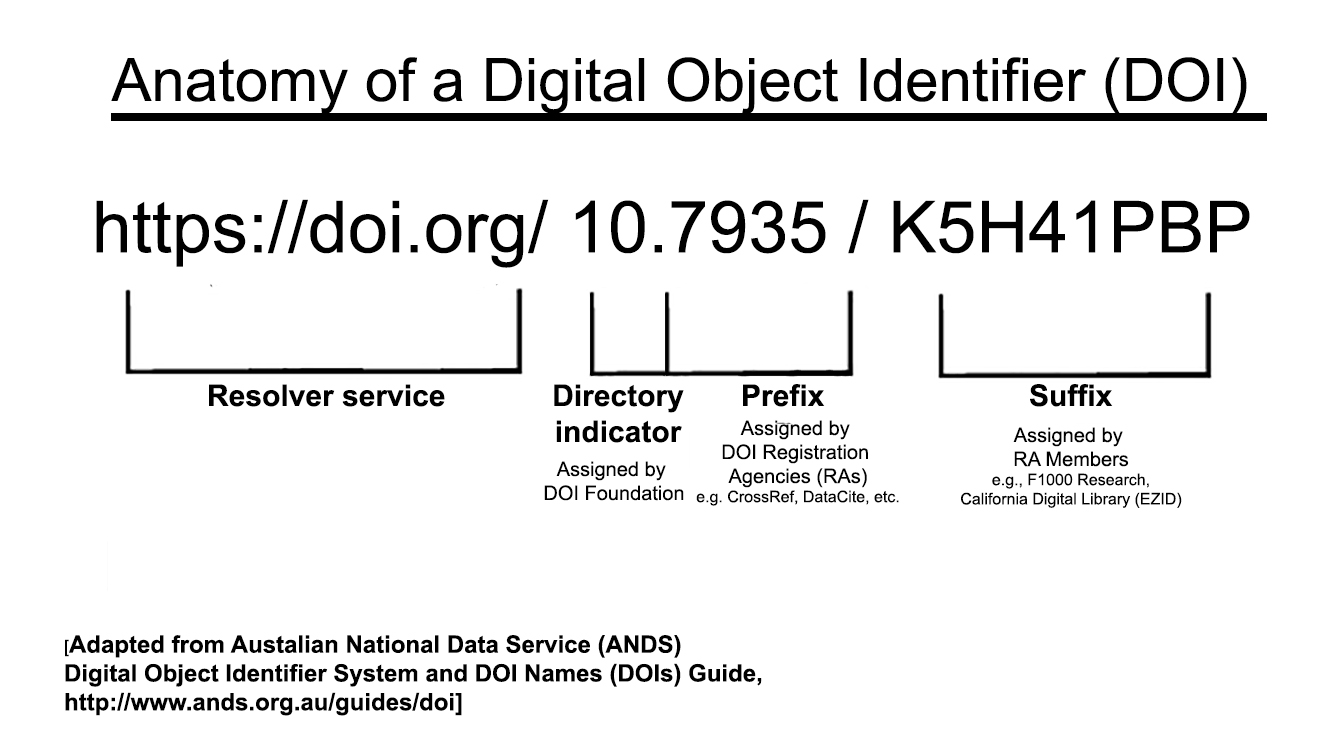
This lesson explores the anatomy of a DOI, how it is generated, what metadata is associated, and how to get a DOI for a new work.
$ curl -s -S http://dx.doi.org/10.1103/PhysRev.109.193
$ curl -s -S http://dx.doi.org/10.7935/K5H41PBP
Whose websites did the redirects for each DOI take you to?
$ curl -s -S -L http://dx.doi.org/10.1103/PhysRevLett.116.061102 >redirect1.txt
$ grep "citation_title" redirect1.txt
$ curl -s -S -L http://dx.doi.org/10.7935/K5H41PBP >redirect2.txt
$ grep "title" redirect2.txt
$ curl -s -S -L http://dx.doi.org/10.5454/JPSv1i220161014 | grep "title"
Note: The faux DOI used in this example was assigned by an established publisher to detect and block unauthorized access to their system. The controversy surrounding publisher creation of DOI-like strings for business operations was taken up in an interesting posting on the CrossRef blog, DOI like strings and fake DOIs.
$ curl -s -S -L http://dx.doi.org/10.7935/K5MW2F23 >ex1A4.txt
$ less ex1A4.txt
What format is the landing page provided in?
To make the retrieved data easier to read, remove the markup using the the Unix stream editor sed. A regular expression is used to represent all unwanted content between html brackets.
$ sed -e 's/<[^>]*>//g' ex1A4.txt > ex1A4_pretty.txt
The International DOI System is the overall infrastructure by which Digital Object Identifiers are assigned, registered, resolved, and associated with valuable metadata including citation, availability of full text, funder information, licensing information, and more. The following components of the DOI System together make it work:
The metadata associated with the DOI is often rich enough to provide useful data for a researcher. This lesson and the next look at the array of useful public data associated with DOIs.
$ curl -s -S -L http://dx.doi.org/10.1103/PhysRev.109.193 >landing1.txt
$ curl -s -S -L http://dx.doi.org/10.7935/K5H41PBP >landing2.txt
$ wc landing*.txt
$ curl http://doi.crossref.org/doiRA/10.5170/CERN-2000-001.101
$ curl http://doi.crossref.org/doiRA/10.5170/CERN-2000-001.101, doi.crossref.org/doiRA/10.2307/1578389
Note that this handy lookup service is provided by one of the Registration Agencies, CrossRef, yet the query also works for DOIs issued by other Registration Agencies! This demonstrates that each DOI Agency provides an array of services beyond registering and maintaining DOIs for their members; savvy researchers may wish to check with more than one RA to get useful information.
$ curl -s -S http://api.datacite.org/members >datacite.txt
$ less datacite.txt
Note that the data comes from the Datacite API in JSON format (Javascript Object Notation) – an increasingly popular metadata standard for Web services. JSON is great for machines to read, but not so much for humans! So let’s convert it to something easier on the eyes.
$ cat datacite.txt | tr ',' '\012' >datacite_pretty.txt
$ less datacite_pretty.txt
When works are registered with DOI Registration Agencies, the Registrant (publisher, data center, or other information provider) is required to submit metadata about the resource that the DOI links to. Each Registration Agency maintains its own metadata schema and establishes rules for requiring and populating the metadata elements so it is important to check their respective websites for a list of metadata elements used and whether they are mandatory or optional.
Each Registration Agency also has the option of offering metadata look up and harvesting services that researchers may openly query. At a minimum, these services provide a basic citation for each DOI-assigned work: creator, title, publisher, publication year, and URL for the landing page of the resource. Additional metadata may include references cited in the work; funding sources; author ORCiD numbers; usage licenses attached to the work; and more.
Researchers may search for metadata associated with DOIs in various ways. This module demonstrates how to use the API services of two Registration Agencies – CrossRef and DataCite – to query and retrieve valuable metadata about research outputs. The commands demonstrated use the process of DOI Content Negotiation to retrieve different representations of a work from the API service.
$ curl http://api.crossref.org/works/http://dx.doi.org/10.1103/PhysRevLett.116.061102 > cite1.txt
$ less cite1.txt
The retrieved citation is in JSON format – a popular way for presenting citation metadata that can be parsed by machines. But what if you need a different citation format for your purposes? Let’s try Content Negotation to specify that we want the citation provided in BibTeX, a citation format used in many research information systems.
$ curl -LH "Accept:text/bibliography; style=bibtex" http://dx.doi.org/10.1103/PhysRevLett.116.061102 > cite1.bib | cat cite1.bib |tr ',' '\012'
Do you know of any research information services that automatically ingest citations in BibTeX? (Cue the ORCiD system) Keep this citation in its BibTeX for Lessons 2 and 3, where we add it to a publications list to cite in a new research paper.
You have a few options:
Note that Zenodo does offer an API service which can be used via Python with the Requests package installed. Advanced registration with Zenodo is necessary to obtain a authorization token to include in requests.
Point your web browser to Zenodo:
http://zenodo.org
Search or browse for the many different types of research resources deposited it for sharing. Are you surprised by the many different types of objects being deposited and assigned DOIs?
This exercise applies various UNIX commands to answer the question “What types of works can be assigned DataCite DOI’s and how many types?”
$ curl https://api.datacite.org/work-types > works_raw.txt
$ head works_raw.txt
$ cat works_raw.txt | tr ',' '\012' > works_clean.txt
$ cat works_clean.txt | grep "title" | cut -d : -f 3 > works_final.txt
$ cat works_final.txt | wc -l